Learn Python
Learn Data Structure & Algorithm
Learn Numpy
Learn Pandas
Learn Matplotlib
Learn Seaborn
Learn Statistics
Learn Math
Learn MATLAB
introduction
Setup
Read data
Data preprocessing
Data cleaning
Handle date-time column
Handling outliers
Encoding
Feature_Engineering
Feature selection filter methods
Feature selection wrapper methods
Multicollinearity
Data split
Feature scaling
Supervised Learning
Regression
Classification
Bias and Variance
Overfitting and Underfitting
Regularization
Ensemble learning
Unsupervised Learning
Clustering
Association Rule
Common
Model evaluation
Cross Validation
Parameter tuning
Code Exercise
Car Price Prediction
Flight Fare Prediction
Diabetes Prediction
Spam Mail Prediction
Fake News Prediction
Boston House Price Prediction
Learn Github
Learn OpenCV
Learn Deep Learning
Learn MySQL
Learn MongoDB
Learn Web scraping
Learn Excel
Learn Power BI
Learn Tableau
Learn Docker
Learn Hadoop
Everything about ensemble learning?
What is Ensemble learning?
Suppose you want to buy a phone and you are confused that which phone you should buy. So you asked one of your friends and he suggest you buy an Apple phone. Now if you buy a phone depending on one person opinion that can be wrong but if you asked your all the friends and then combine each friends suggestion and then see which phone gets most of the vote and after this if you take a decision that which phone you should buy, will be more useful and appropriate. So the idea of ensemble learning is the same. It says that don't depend on one ml model output, use multiple models and then combine those model output and do vote and then make a decision. Ensemble learning uses the dataset on a different model and then combine all those model outputs and then do vote that which output is mostly predicted and then take a decision. Suppose we have a dataset. Now pass those data on five different models and then combine all the output coming from all the models and then do vote. After voting takes a decision or prediction or output. This model removes the bias of the data or models.
Types of ensemble learning method:
How Bagging works?
Bagging is not a sequential ensemble method. Here one model doesn't depend on the previous model. Suppose
there are three ml models m1,m2,m3. So m2 model doesn't depend on m1 model and m3 model is don't depend on m2
model. They work independently. Bagging is a technique where bags of data are created from actual data.
Suppose you have 100 records in a dataset. Randomly take 25 records from that dataset and create a new dataset
or one bag, then again randomly take 20 data from the main dataset and create a 2nd bag or new dataset. Bags
or new datasets will be created like this according to the needs. Remember one thing, this selection is with
replacement selection. It means that after creating one bag or one dataset by doing a random selection from
the original dataset, the selected data will go back in the main dataset again and then a new bag or new
dataset will be created. It means bags can have duplicate records. For example, the number one bag and number
two bag can have the same records. Bags can have all the same data or some same data like number 1 row of the
main dataset is present in all the bags or some bags and it also can be possible that number 1 record is
present in only one bag or no 1 record is present in all the bags. After creating the bags the number of the
model will be used equally to the number of bags or datasets. If 5 bags are created then 5 different models
will be used. After training each model will give one output. Then combine all those model outputs and then do
vote that which output is mostly predicted and then get the final output.
Types of bagging technique:
Random Forest
How Boosting works?
Boosting is a sequential ensemble method. Here one model is dependent on the previous model. Suppose there are
three models m1,m2,m3. So m2 model depends on m1 model and m3 model is dependent on m2 model. Suppose you have
dataset which have 10 records(1,2,3,4,5,6,7,8,9,10). Boosting add weight to all the records. The first time
all the weights of each record are the same so the probability of each data to select for the first bag or
dataset is equal. After this random sampling happens. It means picking data randomly from the main dataset and
creating a new dataset or bag. For example, in the first bag, you have records number 1,3,5,7. After creating
the first bag or first dataset you will use a ml model on that dataset to train. After training pass the main
dataset as testing data for the test that models what you just trained by the first bag or sample dataset.
After passing the data the model will do a prediction. The model will predict some correctly and some wrong.
For example, the model predicts records number 4,2,9 wrong. Now those records which were predicted wrong, you
will increase those records weights. Because of increasing the weights, now the probability of those records
which predicted wrong, to select for the second bag or dataset is increased more than other records. Now when
you create a second bag, those records which are predicted wrong by the first model will go ahead to the
second dataset or bag, then if you want to add more then you can add some more. Suppose this time you have
selected 4,2,9,10(4,2,6 was predicted wrong) records for the second bag or dataset. Now again fit a ml model
to the second dataset and will train the model. After training again pass the main dataset as testing data for
the test. This time again second model will do some right predictions and some wrong predictions. Suppose this
time it's predicted 1,3,8 records wrong. So again increase the weight of wrong predicted records and again
create a new bag or dataset and train the dataset with a new model and again test the model by the main
dataset. So this process will happen to all the bags or datasets that you want to create. After this process
combines all the output and do votes and then will get the final output.
Types of boosting technique:
How AdaBoost works?
In AdaBoost, trees are used as dataset/bag/base learner/weak learner to train. The trees in the AdaBoost have
only one root node and two leaf nodes. This small tree is called stumps. In AdaBoost trees are not like
decision trees or random forest algorithm trees, which means in the decision tree or random forest trees have
root node then too many child nodes, and those child nodes have too many leaf nodes means a big tree but in
AdaBoost, the tree has only one root node and that root node have only two leaf nodes. Stumps are created for
each independent variable. After this you compare the entropy of stumps with each other and try to find which
stumps entropy is less than other and then you select that stump for the dataset/bag/base learner/weak learner
to train the model.
Let's see an example for better understanding:
Suppose you have dataset which contain 10 records(1,2,3,4,5,6,7,8,9,10). Adaboost will add weight to all the
records.
The formula for weight assigning is,
w=1/n
n= total number of records.
We have 10 records so the weight will be 1/10. So each record will get a weight of 1/10. The sum of all the
weights of all records is 1. The first time all the weights of each record are the same so the probability of
each data to select for the first bag or dataset is equal. After this do random sampling to create a new
dataset or bag. For example, in the first bag, there are record numbers 1,3,5,7. After creating the first bag
or the first dataset, use a ml model on that dataset to train. In the model, stumps will be used. After
training pass the main dataset as testing data for testing the model that you just trained by the first bag or
sample dataset. After passing the data the model will predict some data correctly and predict some data wrong.
For example, the model predicts record numbers 4,2,9 wrong. Now those records which were predicted wrong,
increase those records weights and decrease other records' weight for balance. Because of increasing the
weights, now the probability of those records which predicted wrong, to select for the second bag or dataset
is increases or more than other records. Now create a second bag and those records which are predicted wrong
by the first model will go ahead to the second dataset or bag, then if there you want to add more then add
some more. Suppose this time the second bag has 4,2,9,10(4,2,6 was predicted wrong by the first model)
records. Now again fit the ml model to the second dataset and train the model(here you will use stumps).After
training again pass the main dataset as testing data for the test. This time again the second model will do
some right predictions and some wrong predictions. Suppose this time it's predicted 1,3,8 record wrong. So
again increase the weight of wrong predicted records and again create a new bag or dataset and train the
dataset with a ml model and test the data again. So this process will happen to all the bags or datasets you
want to create. After this process combines all the output and do votes and then you will get the final
output.
How Gradient boost works?
In AdaBoost, the learning happens by updating the weights but in gradient boost, the learning happens by
optimizing the loss function. The loss function is a function that helps to find the difference between the
actual value and predicted value and optimization means gradient boost tries to reduce the loss value and make
it near to zero. In gradient boost, the trees can have leaf nodes between 8-32. In gradient boost first step
is to find a predicted value without using any ml model.
how to find the predicted value without using any model? The answer is gradient boost will do this by
finding the average of the target variable/column. Suppose if you have 5 values in the target column then it
will add those values and divide them with the total number of values. In this way, you get the predicted
value. For all records of the target column, the predicted value is the same. The second step is to find the
residuals. Residuals mean the difference between the predicted value and the actual value. To find residuals
subtract each record of the target column by predicted value. After getting the residuals, the residual column
will be the current target column and fit a model for training. After training it will predict some new
residual for each record of the main dataset. Now add those residuals with the predicted column that you got
by finding the mean of the main target column. After doing this our first model work is done. Then again find
a new residual by subtracting the actual value and new main predicted value. Then again set residual as target
column, then again fit a model means all the process will repeat.
Let's see an example for better understanding:
| AGE | BMI | Height |
|---|---|---|
| 21 | 24 | 174 |
| 24 | 26 | 176 |
| 25 | 27 | 180 |
| 57 | 35 | 169 |
| 67 | 38 | 164 |
| 70 | 40 | 170 |
| 75 | 42 | 150 |
| 85 | 45 | 187 |
In the data set dependent or target variable is height. According to step one, you have to find the predicted
value without using any model of the target column.
To do this you calculate the mean of the target column.
So here the
predicted value will be=(174+176+180+169+164+170+150+187)/8=171.
So now for each record of the target
column, the predicted value is 171. Now find the residual. To find it subtract actual value and predicted
value.
After the calculation:
| AGE | BMI | Height | Predicted value | Residual |
|---|---|---|---|---|
| 21 | 24 | 174 | 171 | 3 |
| 24 | 26 | 176 | 171 | 5 |
| 25 | 27 | 180 | 171 | 9 |
| 57 | 35 | 169 | 171 | -2 |
| 67 | 38 | 164 | 171 | -7 |
| 70 | 40 | 170 | 171 | -1 |
| 75 | 42 | 150 | 171 | -21 |
| 85 | 45 | 187 | 171 | 16 |
After finding the residual, now residual will become the target column, and the other two columns mean AGE and
BMI are independent variable/columns. For this new target column(residual), fit a model where the target
variable is residual and the independent variable is AGE and BMI. After training the model you will get a new
prediction. Because the target variable is residual so the prediction of ml model for each record will be a
new predicted residual. After getting the new predicted residual, the predicted column which you got by doing
the mean of height column will be changed.
The formula to get new predicted column value:
New predicted value=previous predicted value+η*new predicted residual
η=learning rate
Learning rate means at what shift or speed you want to change the predicted value. Let's take leaning rate as
0.1.
new predicted values:
| AGE | BMI | Height | New Predicted value | Old Residual | New Residual |
|---|---|---|---|---|---|
| 21 | 24 | 174 | 171.35 | 3 | 3.5 |
| 24 | 26 | 176 | 171.52 | 5 | 5.2 |
| 25 | 27 | 180 | 171.90 | 9 | 9.5 |
| 57 | 35 | 169 | 170.80 | -2 | -1 |
| 67 | 38 | 164 | 170.30 | -7 | -6.5 |
| 70 | 40 | 170 | 170.90 | -1 | -0.8 |
| 75 | 42 | 150 | 168.90 | -21 | -20 |
| 85 | 45 | 187 | 172.60 | 16 | 16.8 |
After updating or getting a new predicted value first ml model work is done.
Now work with the second
model.
For the second model again find a new residual by the subtraction of the main target
column(Height) and the new predicted value that you got by calculation from the first ml model. After doing
this you will again get the new residual and it will again become a new target column.
| AGE | BMI | Height | New Predicted value | Old Residual |
|---|---|---|---|---|
| 21 | 24 | 174 | 171.35 | 2.65 |
| 24 | 26 | 176 | 171.52 | 4.48 |
| 25 | 27 | 180 | 171.90 | 8.10 |
| 57 | 35 | 169 | 170.80 | -1.80 |
| 67 | 38 | 164 | 170.30 | -6.30 |
| 70 | 40 | 170 | 170.90 | -0.90 |
| 75 | 42 | 150 | 168.90 | -18.90 |
| 85 | 45 | 187 | 172.60 | 14.40 |
Then fit a ml model and will again get new predicted residuals. Then again update the predicted value that you
got after calculation of predicted value+η*new residuals in the first ml model. After updating the second
model's predicted value for each records the work of the second model will also be done.
After the second model, you work on will look something like this:
| AGE | BMI | Height | New Predicted value | Old Residual | New Residual |
|---|---|---|---|---|---|
| 21 | 24 | 174 | 171.35 | 2.65 | 1.90 |
| 24 | 26 | 176 | 171.52 | 4.48 | 5.70 |
| 25 | 27 | 180 | 171.90 | 8.10 | 7.70 |
| 57 | 35 | 169 | 170.80 | -1.80 | -0.60 |
| 67 | 38 | 164 | 170.30 | -6.30 | -5.80 |
| 70 | 40 | 170 | 170.90 | -0.90 | -0.20 |
| 75 | 42 | 150 | 168.90 | -18.90 | -18.10 |
| 85 | 45 | 187 | 172.60 | 14.40 | 13.80 |
So this process will happen to all the models that will be created in gradient boosting. Look at the residual after every model completes their work the residual is reducing means it's coming near to zero and the prediction values are also going near to the actual values.
XGBoost
What is XGBoost?
XGboost stands for extreme gradient boost. XG boost is an advanced technique of gradient boost. Decision trees
are used in both boost and gradient boost models.
Basic things which make XGboost advance from Gradient boost:
When the sign of residuals is opposite then you will get a lower similarity score, it happens because the opposite sign similarity score cancels each other and if not then you will get a higher similarity score. Here lambda is used to control ss. Lambda adds a penalty in ss. This penalty helps to shrink extreme leaf or node weights which can stabilize the model at the cost of introducing bias.
How XGBoost Works?
Because XGBoost is an extreme or advanced version of gradient boost so the basic working process will be the
same. So before learning about the xgboost working process you must know how gradient boost works. In XGBoost
main working process like, find a basic prediction of the main target column by finding the mean of that
target column, then find the residuals and then make residuals as the target, then train model, then again get
new residuals as prediction, then add new residuals with basic prediction, then again find new residuals, then
again train new model everything is same but the difference is how you create the tree, how you add tree
predictions residual with basic prediction and what you will get by finding mean of the main target column.
To create a tree first take residuals for the root node. Then use conditions and split nodes like a normal
tree. Trees are created in XGBoost normally like how you create in a decision tree. But here in each node, you
calculate the similarity score. For one node and its child nodes, you calculate the gain value and you also
have a value called gamma. With these values, you can control the overfitting of the decision tree and can get
good accuracy. If the gamma value is less than the gain value then only the tree grows or that node can go
forward otherwise not. By doing this you perform auto pruning and control overfitting.
How to add ml prediction value with basic prediction:
Formula: New prediction=previous prediction+(η*Model residual prediction)
So xgboost also works on residuals and tries to reduce it to get better prediction or accuracy like gradient
boost. But here some extra parameters are used like gamma, eta, ss, gain, lambda or do some extra work to
perform better from gradient boost.
Let's see a example:
This is the data and here dependent column is IQ.
| AGE | IQ |
|---|---|
| 20 | 38 |
| 15 | 34 |
| 10 | 20 |
Let's find the predicted value and residuals. To get the predicted value to calculate the mean of the
dependent variable and here that is 30. To find the residuals subtract the dependent variable with the
predicted value.
| AGE | IQ | Predicted value | Residual |
|---|---|---|---|
| 20 | 38 | 30 | 8 |
| 15 | 34 | 30 | 4 |
| 10 | 20 | 30 | -10 |
Lets calculate the similarity score:
First put ƛ as 0
Formula:Similarity Score = (S.R2) / (N + ƛ)
Similarity Score(SS) = (-10+4+8)2 / 3+0 = 4/3 = 1.33
Now make a decision tree.
Let's set the tree splitting criteria for Age greater than 10(>10).
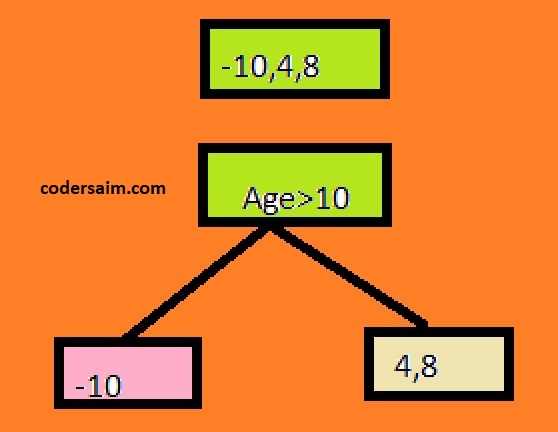
Now calculate SS and the gain.
For left side leaves the ss:
SS=(-10)^2/ 1+0=100
For right side leaves the ss:
SS=(4+8)^2/ 2+0=72
gain=(100+72)-1.33=
Now if the gain is greater than the gamma value only then the splitting will happen of these leaves. For
example, let's take the gamma value as 135. So here gain value is greater than gamma so the splitting will
happen.
Now let's see the prediction:
Formula: New prediction=previous prediction+(η*Model residual prediction)
Now put the values in the formula and get the new prediction. Then all those processes will happen again and
again until the residuals become zero.
XGBoost Regression Practical implementation
!pip install xgboost
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
from xgboost import XGBRegressor
df = pd.read_csv("D:/car data.csv")
'''
Dataset link: https://www.kaggle.com/datasets/nehalbirla/vehicle-dataset-from-cardekho?select=car+data.csv
'''
df.head()
#Label encoding
df.replace({"Fuel_Type":{"Petrol":2,"Diesel":1,"CNG":0}},inplace=True)
df.replace({"Seller_Type":{"Dealer":1,"Individual":0}},inplace=True)
df.replace({"Transmission":{"Manual":1,"Automatic":0}},inplace=True)
df.drop(columns=["Car_Name"], axis=1,inplace=True)
df.head()
#Scaling the data
independent_var=df.drop(columns=["Selling_Price"], axis=1)
scaler= StandardScaler()
transform_scale_data=scaler.fit_transform(independent_var)
transform_scale_data
#Separating the independent var and target var
X=transform_scale_data
Y=df["Selling_Price"]
#Splitting data into train and test data
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.2, random_state=1)
#Training the model
model = XGBRegressor(objective ='reg:linear', colsample_bytree = 0.3, learning_rate = 0.1, max_depth = 5, alpha = 10, n_estimators = 10)
'''
1. learning_rate: It is the step size of shrinkage used to prevent overfitting problem. The range is between 0 to 1
2. max_depth: It determines that, how deeply a tree is allowed to grow during any boosting round.
3. colsample_bytree: It is the percentage of features used per tree. If we use high value then it can lead to overfitting.
4. n_estimators: Here we define the number of trees we want to build.
5. gamma: controls the splitting of given node according to the o expected reduction in loss after the split.
6. alpha: It is L1 regularization. Use larger value for more regularization.
7. lambda:It is L2 regularization. It is more smoother compare to L1 regularization.
'''
xg_reg.fit(X_train,y_train)
#prediction on the training data
training_data_prediction=model.predict(X_train)
training_data_prediction
#R squared error training data
score_using_r2_score=metrics.r2_score(Y_train,training_data_prediction)
score_using_r2_score
#prediction on the testing data
testing_data_prediction=model.predict(X_test)
testing_data_prediction
#R squared error testing data
score_using_r2_score=metrics.r2_score(Y_test,testing_data_prediction)
score_using_r2_score
XGBoost Classifier Practical implementation
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
df = pd.read_csv("D:/sonar data.csv",header=None)
'''
Dataset link: https://www.kaggle.com/datasets/mattcarter865/mines-vs-rockssv
'''
df.head()
#Separating the independent var and target var
X=df.drop(columns=60,axis=1)
Y=df[60]
#Splitting data into train and test data
XX_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.1,stratify=Y, random_state=51)
#Training model
model=XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=500, objective='binary:logistic', booster='gbtree') '''
1. penalty=l1, l2, elasticnet and none. Default is l2.
none means no penalty.
l2 means add a L2 penalty.
l1 means add a L1 penalty.
elasticnet means add both L1 and L2 penalty.
2. random_state =int or RandomState instance. Default is None.
More parameters: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
'''
model.fit(X_train,Y_train)
#Accuracy on training data
X_train_prediction= model.predict(X_train)
training_data_accuracy=accuracy_score(X_train_prediction, Y_train)
print("accuracy on training data:",training_data_accuracy )
#Accuracy on testing data
X_test_prediction= model.predict(X_test)
testing_data_accuracy=accuracy_score(X_test_prediction, Y_test)
print("accuracy on testing data:",testing_data_accuracy )